

国产算法突破:基于消费级GPU的近场动力学计算效率提升800倍
 摘要:
近日,快科技报道了深圳北理莫斯科大学团队研发的一种新型高性能算法,该算法能够显著提升NVIDIA消费级GPU在科学计算领域的性能,最高可达800倍。这一突破性进展主要体现在对近场动...
摘要:
近日,快科技报道了深圳北理莫斯科大学团队研发的一种新型高性能算法,该算法能够显著提升NVIDIA消费级GPU在科学计算领域的性能,最高可达800倍。这一突破性进展主要体现在对近场动... 近日,快科技报道了深圳北理莫斯科大学团队研发的一种新型高性能算法,该算法能够显著提升NVIDIA消费级GPU在科学计算领域的性能,最高可达800倍。这一突破性进展主要体现在对近场动力学(Peridynamics,PD)计算效率的提升上。
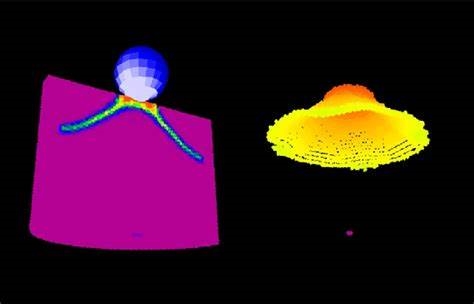
近场动力学是一种非局部力学理论,能够有效模拟材料断裂、损伤等复杂物理现象,在航空航天、土木工程和国防军事等领域具有广泛的应用前景。然而,其计算复杂度高,一直以来是制约其应用的关键瓶颈。传统模拟方法的计算效率低下,难以处理大规模问题。
深圳北理莫斯科大学团队另辟蹊径,基于NVIDIA CUDA编程技术,开发了名为PD-General的新框架。该框架通过优化算法设计和内存管理,充分发挥了GPU的大规模并行计算能力。测试结果显示,在普通的RTX 4070显卡上,PD-General框架相比传统串行算法速度提升了800倍,相比最新的OpenMP并行算法也提升了100倍。
具体而言,在大规模模拟(百万量级粒子)中,新算法可在不到5分钟内完成4000步迭代;在2D单轴拉伸问题中,可在不到2分钟内完成695万次单精度迭代。这种显著的性能提升,将极大地缩短计算时间,加快科研进度,降低计算成本。
更重要的是,该算法无需依赖高性能GPU芯片,突破了美国技术制裁的限制,只需使用普通的消费级GPU即可实现。这对于我国科学研究和产业发展具有重大意义,有助于降低对高性能计算资源的依赖,促进相关领域的自主创新。
然而,目前该算法的应用仍局限于NVIDIA的GPU平台。未来,如果能够实现对国产GPU硬件的支持,则将进一步提升其影响力,彻底摆脱对国外技术的依赖。
这项研究成果不仅为近场动力学模拟提供了强有力的工具,也为其他计算密集型科学计算问题提供了新的思路。相信随着技术的不断成熟和完善,该算法将在更多领域得到广泛应用,推动我国在相关领域的科技进步和产业升级。 未来研究方向可以考虑以下几个方面:
- 算法优化: 进一步优化PD-General框架,例如探索更高级的并行算法和内存管理策略,以提升计算效率和可扩展性。
- 国产GPU适配: 将算法移植到国产GPU平台,以实现自主可控,并充分发挥国产GPU的性能优势。
- 应用拓展: 将该算法应用于更多实际工程问题,例如航空器结构设计、桥梁抗震分析、新型材料研发等,以验证其有效性和实用性。
- 开源共享: 将PD-General框架开源,方便更多科研人员使用和改进,促进学术交流与合作。
总而言之,深圳北理莫斯科大学团队的这项研究成果是国产算法领域的一项重大突破,为我国在科学计算领域实现自主可控奠定了坚实的基础。







还没有评论,来说两句吧...